One of the most commonly requested features by the CERN cloud user community is support for authentication using Kerberos on the command line and single-sign on with the OpenStack dashboard.
In our Windows and Linux environment, we run Active Directory to provide authentication services. During the Essex cycle of OpenStack, we added support for getting authentication based on Active Directory passwords. However, this had several drawbacks:
- When using the command line clients, the users had the choice of storing their password in environment variables such as with the local openrc script or re-typing their password with each OpenStack command. Passwords in environment variables has significant security risks since they are passed to any sub-command and can be read by the system administrator of the server you are on.
- When logging in with the web interface, the users were entering their password into the dashboard. Most of CERN's applications use a single sign on package with Active Directory Federation Services (ADFS). Recent problems such as Heartbleed show the risks of entering passwords into web applications.
The following describes how we configured this functionality.
Approach
With our upgrade to Icehouse completed last week, the new release of the v3 identity API, Keystone now supports several authentication mechanisms through plugins. By default password, token and external authentication were provided. In this scenario, other authentication methods such Kerberos or X.509 can be used with a proper apache configuration and the external plugin provided in keystone. Unfortunately, when enabling these methods on apache, there is no way to make them optional so the client can choose the most appropriate.
Also when checking the projects he can access, the client normally does two operations on keystone, one to retrieve the token, and the other one with the token to retrieve the project list. Even if it is specified in the environment variables, the second call always uses the catalog, so if in the catalog has version 2 and we are using version 3 then we have an exception while doing the API call.
Requirements
In this case we need a solution that allows us to use Kerberos, X.509 or another authentication mechanism in a transparent way and also backwards compatible, so we can offer both APIs and let the user choose which is the most appropriate for its workflow. This will allow us to migrate services from one API version to the next one with no downtime.
In order to allow external authentication to our clients, we need to cover two parts, client side and server side. Client side to distinguish which is the auth plugin to use, and Server side to allow multiple auth methods and API versions at once.
Server Solution
In order to have different entry points under the same api, we would need a load balancer, in this particular case we use HAproxy. From this load balancer we are calling two different sets of backend machines, one for version 2 of the API and the other for version 3. In this loadbalancer, we can analyze the version of the url where the client is connecting to so we can redirect him to the appropriate set. Each backend is running keystone under apachea and it is connected to the same database. We need this to allow tokens to be validated no matter the version is used on the client. The only difference between the backend sets is the catalog, the identity service is different on both pointing the client to the available version on each set. For this particular purpose we will use a templatedcatalog.
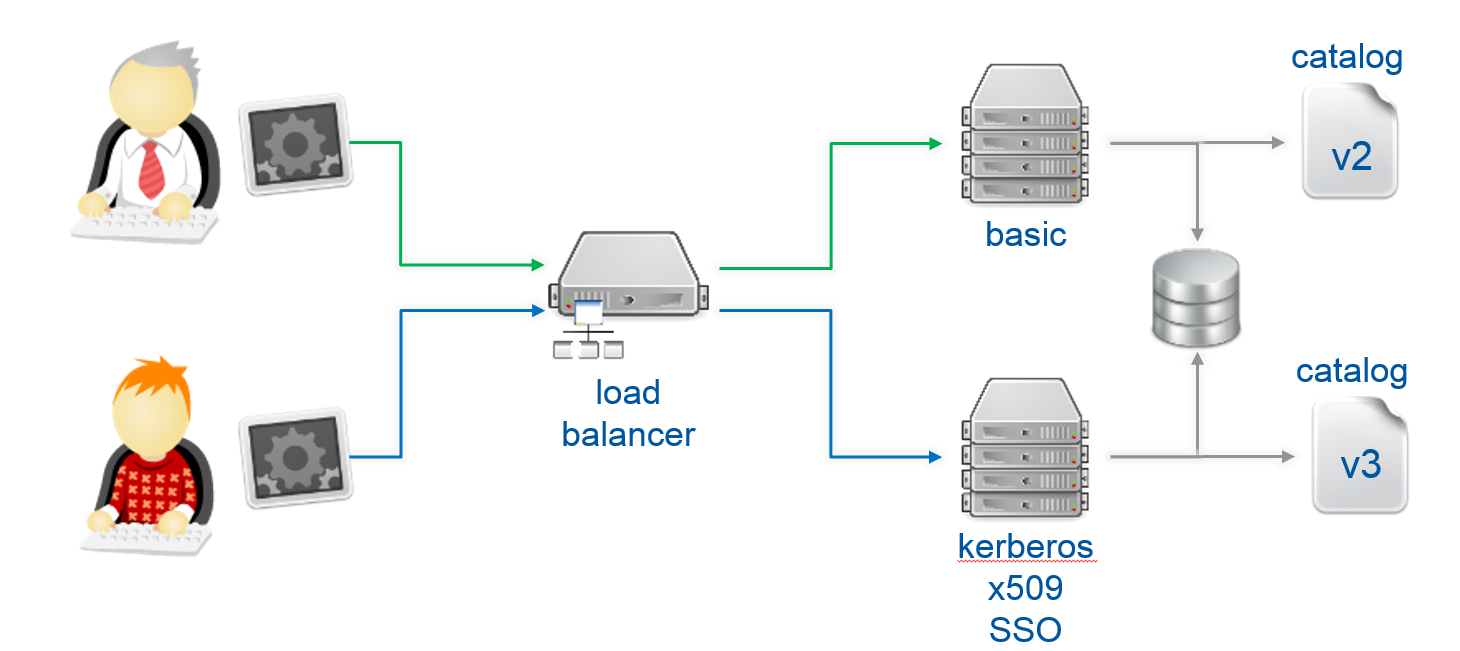
Right now we solve the multiversion issue of the OpenStack environment, but we didn't allow Kerberos or X.509. As these methods are not optional we may need different entry points for each authentication plugin used. So we need entry points for OpenStack authentication (password, token), Kerberos and X.509. There is no issue with the catalog if we enable these methods, all of them can be registered on the service catalog like normal OpenStack authentication, because any consequent call on the system will use token based authentication.
So in the apache v3 backend we have the following urls defined:
https://mykeystone/main/v3
https://mykeystone/admin/v3
https://mykeystone/krb/v3
https://mykeystone/x509/v3
If you post an authentication request to the Kerberos url, this will require a valid Kerberos token, in case it is not sent it will initiate a challenge. After validating it, it will it the user as the REMOTE_USER. In case of client certificate authentication, you will use the X.509 url that will require a valid certificate, in this case it will use the DN as the REMOTE_USER. After this variable is set, then Keystone can take over and check the user in the Keystone database.
There is a small caveat, we cannot do offloading of SSL client authentication on the HAproxy, so for this purpose we need to connect directly from the client, it uses a different port 8443 and connects directly to the backends configured. So for X.509 authentication we use 'https://mykeystone:8443/x509/v3'
Client Solution
For the client side, the plugin mechanism will only be available on the common cli (python-openstackclient) and not on the rest of the toolset (nova, glance, cinder, ...). There is no code yet that implements the plugin functionality, so in order to provide a short term implementation, and based on our current architecture, we can base it the selection of the plugin on the OS_AUTH_URL for the moment. The final upstream implementation will almost certainly differ at this point by using a parameter or discover the auth plugins available. In that case the client implementation may change but this is likely to be close to the initial implementation.
In openstackclient/common/clientmanager.py
...
if 'krb' in auth_url and ver_prefix == 'v3':
LOG.debug('Using kerberos auth %s', ver_prefix)
self.auth = v3_auth_kerberos.Kerberos(
auth_url=auth_url,
trust_id=trust_id,
domain_id=domain_id,
domain_name=domain_name,
project_id=project_id,
project_name=project_name,
project_domain_id=project_domain_id,
project_domain_name=project_domain_name,
)
elif 'x509' in auth_url and ver_prefix == 'v3':
LOG.debug('Using x509 auth %s', ver_prefix)
self.auth = v3_auth_x509.X509(
auth_url=auth_url,
trust_id=trust_id,
domain_id=domain_id,
domain_name=domain_name,
project_id=project_id,
project_name=project_name,
project_domain_id=project_domain_id,
project_domain_name=project_domain_name,
client_cert=client_cert,
)
elif self._url:
...
HAproxy configuration
global
chroot /var/lib/haproxy
daemon
group haproxy
log mysyslogserver local0
maxconn 8000
pidfile /var/run/haproxy.pid
ssl-default-bind-ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128:AES256:AES:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK
stats socket /var/lib/haproxy/stats
tune.ssl.default-dh-param 2048
user haproxy
defaults
log global
maxconn 8000
mode http
option redispatch
option http-server-close
option contstats
retries 3
stats enable
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
frontend cloud_identity_api_production
bind 188.184.148.158:443 ssl no-sslv3 crt /etc/haproxy/cert.pem verify none
acl v2_acl_admin url_beg /admin/v2
acl v2_acl_main url_beg /main/v2
default_backend cloud_identity_api_v3_production
timeout http-request 5m
timeout client 5m
use_backend cloud_identity_api_v2_production if v2_acl_admin
use_backend cloud_identity_api_v2_production if v2_acl_main
frontend cloud_identity_api_x509_production
bind 188.184.148.158:8443 ssl no-sslv3 crt /etc/haproxy/cert.pem ca-file /etc/haproxy/ca.pem verify required
default_backend cloud_identity_api_v3_production
rspadd Strict-Transport-Security:\ max-age=15768000
timeout http-request 5m
timeout client 5m
use_backend cloud_identity_api_v3_production if { ssl_fc_has_crt }
backend cloud_identity_api_v2_production
balance roundrobin
stick on src
stick-table type ip size 20k peers cloud_identity_frontend_production
timeout server 5m
timeout queue 5m
timeout connect 5m
server cci-keystone-bck01 128.142.132.22:443 check ssl verify none
server cci-keystone-bck02 188.184.149.124:443 check ssl verify none
server p01001453s11625 128.142.174.37:443 check ssl verify none
backend cloud_identity_api_v3_production
balance roundrobin
http-request set-header X-SSL-Client-CN %{+Q}[ssl_c_s_dn(cn)]
stick on src
stick-table type ip size 20k peers cloud_identity_frontend_production
timeout server 5m
timeout queue 5m
timeout connect 5m
server cci-keystone-bck03 128.142.159.38:443 check ssl verify none
server cci-keystone-bck04 128.142.164.244:443 check ssl verify none
server cci-keystone-bck05 128.142.132.192:443 check ssl verify none
server cci-keystone-bck06 128.142.146.182:443 check ssl verify none
listen stats
bind 188.184.148.158:8080
stats uri /
stats auth haproxy:NOTAPASSWORD
peers cloud_identity_frontend_production
peer cci-keystone-load01.cern.ch 188.184.148.158:7777
peer cci-keystone-load02.cern.ch 128.142.153.203:7777
peer p01001464675431.cern.ch 128.142.190.8:7777
Apache configuration
WSGISocketPrefix /var/run/wsgi
Listen 443
<VirtualHost *:443>
ServerName keystone.cern.ch
DocumentRoot /var/www/cgi-bin/keystone
LimitRequestFieldSize 65535
SSLEngine On
SSLCertificateFile /etc/keystone/ssl/certs/hostcert.pem
SSLCertificateKeyFile /etc/keystone/ssl/keys/hostkey.pem
SSLCertificateChainFile /etc/keystone/ssl/certs/ca.pem
SSLCACertificateFile /etc/keystone/ssl/certs/ca.pem
SSLVerifyClient none
SSLOptions +StdEnvVars
SSLVerifyDepth 10
SSLUserName SSL_CLIENT_S_DN_CN
SSLProtocol all -SSLv2 -SSLv3
SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128:AES256:AES:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK
SSLHonorCipherOrder on
Header add Strict-Transport-Security "max-age=15768000"
WSGIDaemonProcess keystone user=keystone group=keystone processes=2 threads=2
WSGIProcessGroup keystone
WSGIScriptAlias /admin /var/www/cgi-bin/keystone/admin
<Location "/admin">
SSLRequireSSL
SSLVerifyClient none
</Location>
WSGIScriptAlias /main /var/www/cgi-bin/keystone/main
<Location "/main">
SSLRequireSSL
SSLVerifyClient none
</Location>
WSGIScriptAlias /krb /var/www/cgi-bin/keystone/main
<Location "/krb">
SSLRequireSSL
SSLVerifyClient none
</Location>
<Location "/krb/v3/auth/tokens">
SSLRequireSSL
SSLVerifyClient none
AuthType Kerberos
AuthName "Kerberos Login"
KrbMethodNegotiate On
KrbMethodK5Passwd Off
KrbServiceName Any
KrbAuthRealms CERN.CH
Krb5KeyTab /etc/httpd/http.keytab
KrbVerifyKDC Off
KrbLocalUserMapping On
KrbAuthoritative On
Require valid-user
</Location>
WSGIScriptAlias /x509 /var/www/cgi-bin/keystone/main
<Location "/x509">
Order allow,deny
Allow from all
</Location>
WSGIScriptAliasMatch ^(/main/v3/OS-FEDERATION/identity_providers/.*?/protocols/.*?/auth)$ /var/www/cgi-bin/keystone/main/$1
<LocationMatch /main/v3/OS-FEDERATION/identity_providers/.*?/protocols/saml2/auth>
ShibRequestSetting requireSession 1
AuthType shibboleth
ShibRequireSession On
ShibRequireAll On
ShibExportAssertion Off
Require valid-user
</LocationMatch>
<LocationMatch /main/v3/OS-FEDERATION/websso>
ShibRequestSetting requireSession 1
AuthType shibboleth
ShibRequireSession On
ShibRequireAll On
ShibExportAssertion Off
Require valid-user
</LocationMatch>
<Location /Shibboleth.sso>
SetHandler shib
</Location>
<Directory /var/www/cgi-bin/keystone>
Options FollowSymLinks
AllowOverride All
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
References
The code of python-openstackclient as long as the python-keystoneclient that we are using for this implementation is available at:
We will be working with the community in the Paris summit to find the best way to integrate this functionality into the standard OpenStack release.
The main author is Jose Castro Leon with help from Marek Denis.
Many thanks to the Keystone core team for their help and advice on the implementation.






