
As we increase the number of VMs that we're running on the CERN cloud, we see the impact of a number of configuration choices made early on in the cloud deployment. One key choice is how to schedule VMs across a pool of hypervisors.
We provide our users with a mixture of flavors for their VMs (for details, see http://openstack-in-production.blogspot.fr/2013/08/flavors-english-perspective.html).
During the past year in production, we have seen a steady growth in the number of instances to nearly 7,000.

At the same time, we're seeing an increasing elastic load as the user community explores potential ways of using clouds for physics.

Given that CERN has a fixed resource pool and the budget available is defined and fixed, the underlying capacity is not elastic and we are now starting to encounter scenarios where the private cloud can become full. Users see this as errors when they request VMs that no free hypervisor could be located.
This situation occurs more frequently for the large VMs. Physics programs can make use of multiple cores to process physics events in parallel and our batch system (which runs on VMs) benefits from a smaller number of hosts. This accounts for a significant number of large core VMs.
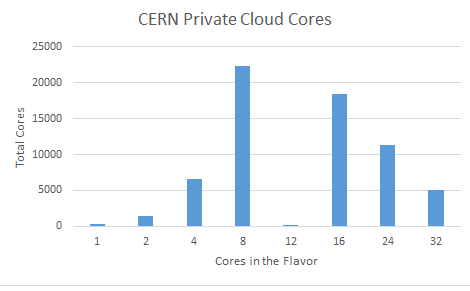
The problem occurs as the cloud approaches being full. Using the default OpenStack configuration (known as 'spread'), VMs are evenly distributed across the hypervisors. If the cloud is running at low utilisation, this is an attractive configuration as CPU and I/O load are also spread and little hardware is left idle.
However, as the utilisation of the cloud increases, the resources free on each hypervisor are reduced evenly. To take a simple case, a cloud with two compute nodes of 24 cores handling a variety of flavors. If there are requests for two 1-core VMs followed by one 24 core flavor, the alternative approaches can be simulated.
In a spread configuration,
- The first VM request lands on hypervisor A leaving A with 23 cores available and B with 24 cores
- The second VM request arrives and following the policy to spread the usage, this is scheduled to hypervisor B, leaving A and B with 23 cores available.
- The request for one 24 core flavor arrives and no hypervisor can satisfy it despite there being 46 cores available and only 4% of the cloud used.
In the stacked configuration,
- The first VM request lands on hypervisor A leaving A with 23 cores available and B with 24 cores
- The second VM request arrives and following the policy to stack the usage, this is scheduled to hypervisor A, leaving A with 22 cores and B with 24 cores available.
- The request for one 24 core flavor arrives and is satisfied by B
A stacked configuration is configured using the RAM weight being negative (i.e. prefer machines with less RAM). This has the effect to pack the VMs. This is done through a nova.conf setting as follows
ram_weight_multiplier=-1.0
When a cloud is initially being set up, the question of maximum packing does not often come up in the early days. However, once the cloud has workload running under spread, it can be disruptive to move to stacked since the existing VMs will not be moved to match the new policy.
Thus, it is important as part of the cloud planning to reflect on the best approach for each different cloud use case and avoid more complex resource rebalancing at a later date.
Thus, it is important as part of the cloud planning to reflect on the best approach for each different cloud use case and avoid more complex resource rebalancing at a later date.
References
- OpenStack configuration reference for scheduling at http://docs.openstack.org/trunk/config-reference/content/section_compute-scheduler.html